Las imágenes se adquieren mediante periféricos especializados tales como escáneres, cámaras digitales de vídeo, cámaras fotográficas, etc. Una imagen, al igual que otros tipos de información, se representa por patrones de bits, generados por el periférico correspondiente.
Existen dos métodos básicos para representar imágenes:
mapas de bits y mapas de vectores.
Los mapas de bits, considera una imagen como una colección de puntos, cada uno de los cuales se llama pixel (abreviatura de “picture element”).
Una imagen en blanco y negro se representa como una cadena larga de bits que representan las filas de píxeles en la imagen, donde cada bit es bien 1 o bien 0, dependiendo de que el pixel correspondiente sea blanco o negro.
En el caso de imágenes en color, cada pixel se representa por una combinación de bits que indican el color del pixel.
Cuando se utilizan técnicas de mapas de bits, el patrón de bits resultante se llama mapa de bits, significando que el patrón de bits resultante que representa la imagen es poco más que un mapa de la imagen.
Muchos de los periféricos de computadora —tales como cámaras de vídeo, escáneres, etc.— convierten imágenes de color en formato de mapa de bits.
Los formatos más utilizados en la representación de imágenes se muestran en la Tabla 1.4.
Mapas de vectores.
Otros métodos de representar una imagen se fundamentan en descomponer la imagen en una colección de objetos tales como líneas, polígonos y textos con sus respectivos atributos o detalles (grosor, color, etc.).
La información en formato de texto se representa mediante un código en el que cada uno de los distintos símbolos del texto (tales como letras del alfabeto o signos de puntuación) se asignan a un único patrón de bits.
El texto se representa como una cadena larga de bits en la cual los sucesivos patrones representan los sucesivos símbolos del texto original.
En resumen, se puede representar cualquier información escrita (texto) mediante caracteres.
Los caracteres que se utilizan en computación suelen agruparse en cinco categorías:
1. Caracteres alfabéticos (letras mayúsculas y minúsculas A, B, C, D, E, … X, Y, Z, a, b, c, … , X, Y, Z
2. Caracteres numéricos (dígitos del sistema de numeración). 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 sistema decimal
3. Caracteres especiales (símbolos ortográficos y matemáticos no incluidos en los grupos anteriores). { } Ñ ñ ! ? & > # ç …
4. Caracteres geométricos y gráficos (símbolos o módulos con los cuales se pueden representar cuadros, figuras geométricas, iconos, etc. | —| ||—— ♠ ∼ …
5. Caracteres de control (representan órdenes de control como el carácter para pasar a la siguiente línea [NL] o para ir al comienzo de una línea [RC, retorno de carro, “carriage return, CR”] emitir un pitido en el terminal [BEL], etc.).
Al introducir un texto en una computadora, a través de un periférico, los caracteres se codifican según un código de entrada/salida de modo que a cada carácter se le asocia una determinada combinación de n bits.
Los códigos más utilizados en la actualidad son:
EBCDIC, ASCII y Unicode.
• Código EBCDIC (Extended Binary Coded Decimal Inter Change Code).
Este código utiliza n = 8 bits de forma que se puede codificar hasta m = 28 = 256 símbolos diferentes. Éste fue el primer código utilizado para computadoras, aceptado en principio por IBM.
• Código ASCII (American Standard Code for Information Interchange).
El código ASCII básico utiliza 7 bits y permite representar 128 caracteres (letras mayúsculas y minúsculas del alfabeto inglés, símbolos de puntuación, dígitos 0 a 9 y ciertos controles de información tales como retorno de carro, salto de línea, tabulaciones, etc.). Este código es el más utilizado en computadoras, aunque el ASCII ampliado con 8 bits permite llegar a 28 (256) caracteres distintos entre ellos ya símbolos y caracteres especiales de otros idiomas como el español.
Código Unicode
Aunque ASCII ha sido y es dominante en la representación de los caracteres, hoy día se requiere de la necesidad de representación de la información en muchas otras lenguas, como el portugués, español, chino, el japonés, el árabe, etc. Este código utiliza un patrón único de 16 bits para representar cada símbolo, que permite 216 bits o sea hasta 65.536 patrones de bits (símbolos) diferentes.
Desde el punto de vista de unidad de almacenamiento de caracteres, se utiliza el archivo (fichero).
Un archivo consta de una secuencia de símbolos de una determinada longitud codificados utilizando ASCII o Unicode y que sedenomina archivo de texto.
Es importante diferenciar entre archivos de texto simples que son manipulados por losprogramas de utilidad denominados editores de texto y los archivos de texto más elaborados que se producen por los procesadores de texto, tipo Microsoft Word.
Ambos constan de caracteres de texto, pero mientras el obtenido con el editor de texto, es un archivo de texto puro que codifica carácter a carácter, el archivo de texto producido por un procesador de textos contiene números, códigos que representan cambios de formato, de tipos de fuentes de letra y otros, e incluso pueden utilizar códigos propietarios distintos de ASCII o Unicode.
Representación de valores numéricos
El almacenamiento de información como caracteres codificados es ineficiente cuando la información se registra como numérica pura.
Veamos esta situación con la codificación del número 65; si se almacena como caracteres ASCII utilizando un byte por símbolo, se necesita un total de 16 bits, de modo que el número mayor que se podía almacenar en 16 bits (dos bytes) sería 99.
Sin embargo, si utilizamos notación binaria para almacenar enteros, el rango puede ir de 0 a 65.535 (216 – 1) para números de 16 bits. Por consiguiente, la notación binaria (o variantes de ellas) es la más utilizada para el almacenamiento de datos numéricos codificados.
La solución que se adopta para la representación de datos numéricos es la siguiente:
Al introducir un número en la computadora se codifica y se almacena como un texto o cadena de caracteres, pero dentro del programa a cada dato se le envía un tipo de dato específico y es tarea del programador asociar cada dato al tipo adecuado correspondiente a las tareas y operaciones que se vayan a realizar con dicho dato.
El método práctico realizado por la computadora es que una vez definidos los datos numéricos de un programa, una rutina (función interna) de la biblioteca del compilador (traductor) del lenguaje de programación se encarga de transformar la cadena de caracteres que representa el número en su notación binaria.
Existen dos formas de representar los datos numéricos: números enteros o números reales.
Representación de enteros
Los datos de tipo entero se representan en el interior de la computadora en notación binaria. La memoria ocupada por los tipos enteros depende del sistema, pero normalmente son dos, bytes (en las versiones de MS-DOS y versiones antiguas de Windows y cuatro bytes en los sistemas de 32 bits como Windows o Linux). Por ejemplo, un entero almacenado en 2 bytes (16 bits):1000 1110 0101 1011
Los enteros se pueden representar con signo (signed, en C++) o sin signo (unsigned, en C++); es decir, números positivos o negativos.
Normalmente, se utiliza un bit para el signo. Los enteros sin signo al no tener signo pueden contener valores positivos más grandes. Normalmente, si un entero no se especifica “con/sin signo” se suele asignar con signo por defecto u omisión.
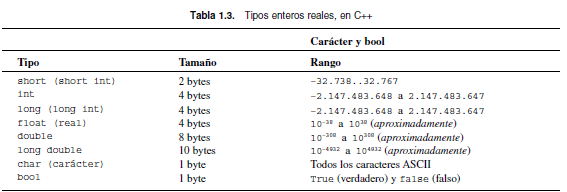
El rango de posibles valores de enteros depende del tamaño en bytes ocupado por los números y si se representan con signo o sin signo (la Tabla 1.3 resume características de tipos estándar en C++).
Representación de reales
Los números reales son aquellos que contienen una parte decimal como 2,6 y 3,14152.
Los reales se representan en notación científica o en coma flotante; por esta razón en los lenguajes de programación, como C++, se conocen como números en coma flotante.
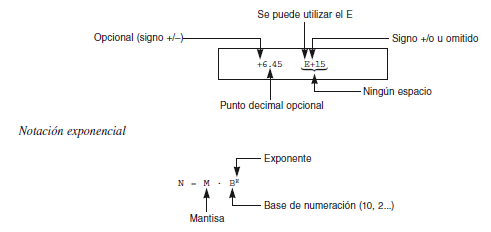
Existen dos formas de representar los números reales. La primera se utiliza con la notación del punto decimal (ojo en el formato de representación español de números decimales, la parte decimal se representa por coma).
La segunda forma para representar números en coma flotante en la notación científica o exponencial, conocida también como notación E.
Esta notación es muy útil para representar números muy grandes o muy pequeños.
Representación de caracteres
Un documento de texto se escribe utilizando un conjunto de caracteres adecuado al tipo de documento. En los lenguajes de programación se utilizan, principalmente, dos códigos de caracteres.
El más común es ASCII (American Standard Code for Information Interchange) y algunos lenguajes, tal como Java, utilizan Unicode (www.unicode.org).
Ambos códigos se basan en la asignación de un código numérico a cada uno de los tipos de caracteres del código.
En C++, los caracteres se procesan normalmente usando el tipo char, que asocia cada carácter a un código numérico que se almacena en un byte.
El código ASCII básico que utiliza 7 bits (128 caracteres distintos) y el ASCII ampliado a 8 bits (256 caracteres distintos) son los códigos más utilizados. Así se pueden representar caracteres tales como ‘A’, ‘B’, ‘c’, ‘$’, ‘4’, ‘5’, etc.
La Tabla 1.3, recoge los tipos enteros, reales y carácter utilizados en C++, la memoria utilizada (número de bytes ocupados por el dato) y el rango de números.
Una computadora es un sistema para procesar información de modo automático.
Un tema vital en el proceso de funcionamiento de una computadora es estudiar la forma de representación de la información en dicha computadora.
Es necesario considerar cómo se puede codificar la información en patrones de bits que sean fácilmente almacenables y procesables por los elementos internos de la computadora.
Las formas de información más significativas son: textos, sonidos, imágenes y valores numéricos y, cada una de ellas presentan peculiaridades distintas.
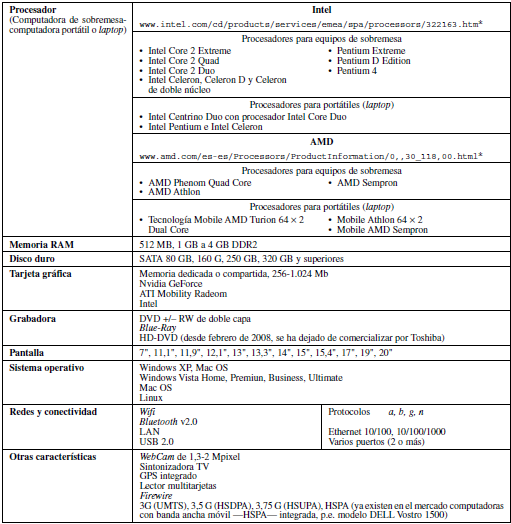
Las computadoras personales que en el primer trimestre de 2008 se comercializan para uso doméstico y en oficinas o en las empresas suelen tener características comunes, y es normal que sus prestaciones sean similares a las utilizadas en los laboratorios de programación de Universidades, Institutos Tecnológicos y Centros de Formación Profesional.
Por estas razones en la Tabla 1.2 se incluyen recomendaciones de características técnicas medias que son, normalmente, utilizadas, para prácticas de aprendizaje de programación, por el alumno o por el lector autodidacta, así como por profesionales en su actividad diaria.
Las computadoras modernas se pueden clasificar en computadoras personales, servidores, minicomputadoras, grandes computadoras (mainframes) y supercomputadoras.
Las computadoras personales (PC) son las más populares y abarcan computadoras portátiles (laptops o notebooks, en inglés) hasta computadoras de escritorio (desktop) que se suelen utilizar como herramientas en los puestos de trabajo, en oficinas, laboratorios de enseñanza e investigación, empresas, etc.
Los servidores son computadoras personales profesionales y de gran potencia que se utilizan para gestionar y administrar las redes internas de las empresas o departamentos y muy especialmente para administrar sitios Web de Internet.
Las computadoras tipo servidor son optimizadas específicamente para soportar una red de computadoras, facilitar a los usuarios la compartición de archivos, de software o de periféricos como impresoras y otros recursos de red. Los servidores tienen memorias grandes, altas capacidades de memoria en disco e incluso unidades de almacenamiento masivo como unidades de cinta magnética u ópticas, así como capacidades de comunicaciones de alta velocidad y potentes CPUS, normalmente específicas para sus cometidos.
Estaciones de trabajo (Workstation) son computadoras de escritorio muy potentes destinadas a los usuarios pero con capacidades matemáticas y gráficas superiores a un PC y que pueden realizar tareas más complicadas que un PC en la misma o menor cantidad de tiempo. Tienen capacidad para ejecutar programas técnicos y cálculos científicos, y suelen utilizar UNIX o Windows NT como sistema operativo.
Las minicomputadoras, hoy día muchas veces confundidas con los servidores, son computadoras de rango medio, que se utilizan en centros de investigación, departamentos científicos, fábricas, etc., y que poseen una gran capacidad de proceso numérico y tratamiento de gráficos, fundamentalmente, aunque también son muy utilizadas en el mundo de la gestión, como es el caso de los conocidos AS/400 de IBM.
Las grandes computadoras (mainframes) son máquinas de gran potencia de proceso y extremadamente rápidas y además disponen de una gran capacidad de almacenamiento masivo. Son las grandes computadoras de los bancos, universidades, industrias, etc.
Las supercomputadoras son las más potentes y sofisticadas que existen en la actualidad;se utilizan para tareas que requieren cálculos complejos y extremadamente rápidos. Estas computadoras utilizan numerosos procesadores en paralelo y tradicionalmente se han utilizado y utilizan para fines científicos y militares en aplicaciones tales como meteorología, previsión de desastres naturales, balística, industria aeroespacial, satélites, aviónica, biotecnología, nanotecnología, etc.
Estas computadoras emplean numerosos procesadores en paralelo y se están comenzando a utilizar en negocios para manipulación masiva de datos. Una supercomputadora, ya popular es el Blue Gene de IBM o el Mare Nostrum de la Universidad Politécnica de Cataluña.
Además de esta clasificación de computadoras, existen actualmente otras microcomputadoras (handheld computers, computadoras de mano) que se incorporan en un gran número de dispositivos electrónicos y que constituyen el corazón y brazos de los mismos, por su gran capacidad de proceso.
Este es el caso de los PDA (Asistentes Personales Digitales) que en muchos casos vienen con versiones específicas para estos dispositivos de los sistemas operativos populares, como es el caso de Windows Mobile, y en otros casos utilizan sistemas operativos exclusivos como es el caso de Symbiam y Palm OS. También es cada vez más frecuente que otros dispositivos de mano, tales como los teléfonos inteligentes, cámaras de fotos, cámaras digitales, videocámaras, etc., incorporen tarjetas de memoria de 128 Mb hasta 4 GB, con tendencia a aumentar.
Las Ciencias de la computación o Informática es la disciplina que trata de establecer una base científica para temas tales como el diseño asistido por computadora, la programación de computadoras, el procesamiento de la información, las soluciones algorítmicas de problemas y el propio proceso algorítmico.
Proporciona los fundamentos para las aplicaciones informáticas actuales, así como la base para la infraestructura de computación del futuro.