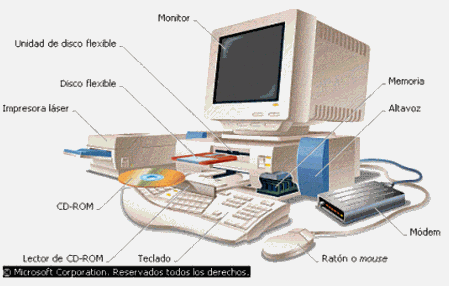
Los dispositivos de Entrada/Salida (E/S) [Input/Output (I/O) en inglés] permiten la comunicación entre la computadora y el usuario.
Los dispositivos de entrada, como su nombre indica, sirven para introducir datos (información) en la computadora para su proceso. Los datos se leen de los dispositivos de entrada y se almacenan en la memoria central o interna.
Los dispositivos de entrada convierten la información de entrada en señales eléctricas que se almacenan en la memoria central. Dispositivos de entrada típicos son los teclados; otros son: lectores de tarjetas —ya en desuso—, lápices ópticos, palancas de mando (joystick), lectores de códigos de barras, escáneres, micrófonos, etc.
Hoy día tal vez el dispositivo de entrada más popular es el ratón (mouse) que mueve un puntero electrónico sobre la pantalla que facilita la interacción usuario-máquina7.
Los dispositivos de salidapermiten representar los resultados (salida) del proceso de los datos. El dispositivo de salida típico es la pantalla (CRT)8 o monitor. Otros dispositivos de salida son: impresoras (imprimen resultados en papel), trazadores gráficos (plotters), reconocedores de voz, altavoces, etc.
El teclado y la pantalla constituyen —en muchas ocasiones— un único dispositivo, denominado terminal. Un teclado de terminal es similar al teclado de una máquina de escribir moderna con la diferencia de algunas teclas extras que tiene el terminal para funciones especiales.
Si está utilizando una computadora personal, el teclado y el
monitor son dispositivos independientes conectados a la computadora por cables. En ocasiones, la impresora se conoce como dispositivo de copia dura (hard copy), debido a que la escritura en la impresora es una copia permanente (dura) de la salida, y en contraste a la pantalla se la denomina dispositivo de copia blanda (soft copy), ya que la pantalla actual se pierde cuando se visualiza la siguiente.
Los dispositivos de entrada/salida y los dispositivos de almacenamiento secundario o auxiliar (memoria externa) se conocen también con el nombre de dispositivos periféricos simplemente periféricos ya que, normalmente, son externos a la computadora.
Estos dispositivos son unidades de discos [disquetes (ya en desuso), CD-ROM, DVD, cintas, etc.], videocámaras, teléfonos celulares (móviles), etc.
Todos los dispositivos periféricos se conectan a las computadoras a través de conectores y puertos (ports) que son interfaces electrónicos.
Los dos componentes principales de una computadora son: hardware y software.
Hardware es el equipo físico o los dispositivos asociados con una computadora. Sin embargo, para ser útil una computadora necesita además del equipo físico, un conjunto de instrucciones dadas.
El conjunto de instrucciones que indican a la computadora aquello que deben hacer se denomina software o programas y se escriben por programadores.
Una red consta de un número de computadoras conectadas entre sí directamente o a través de otra computadora central (llamada servidor), de modo que puedan compartir recursos tales como impresoras, unidades de almacenamiento, etc., y que pueden compartir información.
Una red puede contener un núcleo de PC, estaciones de trabajo y una o más computadoras grandes, así como dispositivos compartidos como impresora.
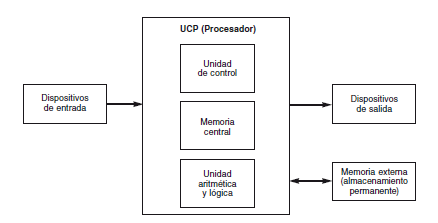
La mayoría de las computadoras, grandes o pequeñas, están organizadas como se muestra en la Figura.
Una computadora consta fundamentalmente de cinco componentes principales: dispositivos de entrada; dispositivos desalida; unidad central de proceso (CPU) o procesador (compuesto de la UAL, Unidad Aritmética y Lógica y la UC, Unidad de Control); la memoria principal o central; memoria secundaria o externa y el programa.
Si a la organización física de la Figura se le añaden los dispositivos para comunicación exterior con la computadora, aparece la estructura típica de un sistema de computadora que, generalmente, consta de los siguientes dispositivos de hardware:
• Unidad Central de Proceso, (CPU, Central Processing Unit).
• Memoria principal.
• Memoria secundaria (incluye medios de almacenamiento masivo como disquetes, memorias USB, discos duros, discos CD-ROM, DVD…).
• Dispositivos de entrada tales como teclado y ratón.
• Dispositivos de salida tales como monitores o impresoras.
• Conexiones de redes de comunicaciones, tales como módems, conexión Ethernet, conexiones USB, conexiones serie y paralelo, conexión Firewire, etc.
Las computadoras sólo entienden un lenguaje compuesto únicamente por ceros y unos. Esta forma de comunicación se denomina sistema binario digital y en el caso concreto de las máquinas computadoras, código o lenguajemáquina.
Este lenguaje máquina utiliza secuencias o patrones de ceros y unos para componer las instrucciones que posteriormente reciben de los diferentes dispositivos de la computadora, tales como el microprocesador, las unidades de discos duros, los teclados, etc.
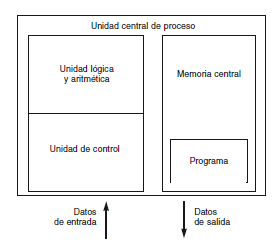
La Figura muestra la integración de los componentes que conforman una computadora cuando se ejecuta un programa; las flechas conectan los componentes y muestran la dirección del flujo de información.
El programa se debe transferir primero de la memoria secundaria a la memoria principal antes de que pueda ser ejecutado. Los datos se deben proporcionar por alguna fuente. La persona que utiliza un programa (usuario de programa) puede proporcionar datos a través de un dispositivo de entrada.
Los datos pueden proceder de un archivo(fichero), o pueden proceder de una máquina remota vía una conexión de red de la empresa o bien la red Internet.
Los datos se almacenan en la memoria principal de una computadora a la cual se puede acceder y manipular mediante la unidad central de proceso (CPU).
Los resultados de esta manipulación se almacenan de nuevo en la memoria principal. Por último, los resultados (la información) de la memoria principal se pueden visualizar en un dispositivo de salida, guardar en un almacenamiento secundario o enviarse a otra computadora conectada con ella en red.
Uno de los componentes fundamentales de un PC es la placa base (en inglés, motherboard o mainboard) que es una gran placa de circuito impreso que conecta entre sí los diferentes elementos contenidos en ella y sobre la que se conectan los elementos más importantes del PC: zócalo del microprocesador, zócalos de memoria, diferentes conectores, ranuras de expansión, puertos, etc.
Los paquetes de datos (de 8, 16, 32, 64 o más bits a la vez) se mueven continuamente entre la CPU y todos los demás componentes (memoria RAM, disco duro, etc.).
Estas transferencias se realizan a través de buses.
Los buses son los canales de datos que interconectan los componentes del PC; algunos están diseñados para transferencias pequeñas y otros para transferencias mayores. Existen diferentes buses siendo el más importante el bus frontal (FSB, Front Side Bus) en los sistemas actuales o bus del sistema (en sistemas más antiguos) y que conectan la CPU o procesador con la memoria RAM.
Otros buses importantes son los que conectan la placa base de la computadora con los dispositivos periféricos del PC y se denominan buses de E/S.
En las primeras máquinas de computación, la complejidad de los algoritmos utilizados estaba restringida por limitaciones tales como la capacidad de almacenamiento de datos y lo intrincado y tedioso de los procedimientos de programación.
Sin embargo, a medida que estas limitaciones comenzaron a desaparecer las máquinas se empezaron a aplicar a tareas cada vez mayores y más complejas.
A medida que los intentos de expresar estas tareas en forma algorítmica comenzaron a plantear problemas a la capacidad de la mente humana, tuvieron que dedicarse cada vez más esfuerzos de investigación al estudio de los algoritmos y al proceso de programación.
Fue en este contexto en el que el trabajo teórico de los matemáticos empezó a dar sus frutos. Como consecuencia del teorema de incompletitud de Gödel, los matemáticos ya habían estado investigando cuestiones relativas a los procesos algorítmicos que los avances de la tecnología estaban entonces planteando.
Con ese bagaje, el escenario estaba dispuesto para la aparición de una nueva disciplina conocida con el nombre de Ciencias de la computación.
Actualmente, las Ciencias de la computación se han consolidado como ciencia de los algoritmos.
El ámbito de esta ciencia es muy amplio, abarcando campos tan diversos como las matemáticas, la ingeniería, la psicología, la biología, la administración empresarial y la lingüística.
De hecho, los investigadores que trabajan en diferentes ramas de las Ciencias de computación pueden tener definiciones muy distintas acerca de dichas ciencias. Por ejemplo, alguien que se dedique a investigar en el campo de la arquitectura de computadoras podría centrarse en la tarea de miniaturización de los circuitos y ver, por tanto, las Ciencias de la computación como una serie de avances tecnológicos junto con una aplicación de los mismos.
Sin embargo, alguien que investigue el campo de los sistemas de bases de datos podría ver las Ciencias de la computación como una manera de buscar la forma de hacer más útiles los sistemas de información.
Y un investigador en el campo de la inteligencia artificial podría considerar las Ciencias de la computación como el estudio de la inteligencia y del comportamiento inteligente.
Cuestiones que nos permitan centrar el estudio de las Ciencias de la computación.
• ¿Qué problemas pueden resolverse mediante procesos algorítmicos?
• ¿Cómo puede facilitarse el descubrimiento de algoritmos?
• ¿Cómo pueden mejorarse las técnicas de representación y comunicación de algoritmos?
• ¿Cómo pueden analizarse y compararse las características de los diferentes algoritmos?
• ¿Cómo pueden utilizarse los algoritmos para tratar la información?
• ¿Cómo pueden aplicarse los algoritmos para generar un comportamiento inteligente?
• ¿Cómo afecta a la sociedad la aplicación de algoritmos?
Abstracción
El concepto de abstracción impregna hasta tal punto el estudio de las Ciencias de la computación y el diseño de los sistemas de computadoras, que nos vemos obligados a tenerlo en cuenta en este capítulo preliminar.
El término abstracción, tal como lo estamos utilizando aquí, hace referencia a la distinción entre las propiedades externas de una entidad y los detalles de la composición interna de la misma.
Es la abstracción lo que nos permite ignorar los detalles internos de un dispositivo complejo tal como una computadora, un automóvil o un microondas y emplearlo como una única unidad comprensible.
Además, es gracias a la abstracción que se pueden diseñar y fabricar dichos sistemas complejos. Las computadoras, los automóviles y los hornos microondas se construyen a partir de componentes, cada uno de los cuales está a su vez construido a partir de otros componentes más pequeños. Cada componente representa un nivel de abstracción, en el sentido de que el uso de ese componente está aislado de los detalles de la composición interna del componente.
Es, por tanto, gracias a que aplicamos la abstracción que somos capaces de construir, analizar y gestionar sistemas de computadoras grandes y complejos que nos resultarían inmanejables si los contempláramos en su totalidad con un nivel detallado.
En cada nivel de abstracción, contemplamos el sistema en términos de una serie de componentes, denominados herramientas abstractas, cuya composición interna ignoramos. Esto nos permite concentrarnos en cómo interactúa con los restantes componentes del mismo nivel y cómo el conjunto de todos los componentes forma un componente de nivel superior. De este
modo, somos capaces de entender la parte del sistema que sea relevante para la parte del sistema que tengamos entre manos, en lugar de perdernos en un océano de detalles.
Conviene recalcar que el concepto de abstracción no está limitado a los campos de la ciencia y la tecnología. Se trata de una técnica importante de simplificación, gracias a la cual nuestra sociedad ha creado un estilo de vida que sería imposible si no utilizáramos ese concepto. Pocos de nosotros comprendemos cómo se implementan en realidad los diversos aparatos, productos y servicios que tan útiles nos son en la vida cotidiana. Ingerimos alimentos y vestimos prendas de ropa que no seríamos capaces de producir por nosotros mismos.
Utilizamos dispositivos eléctricos y sistemas de comunicación sin entender la tecnología subyacente. Empleamos los servicios de otras personas sin conocer los detalles de sus respectivas profesiones. Con cada nuevo avance, una pequeña parte de la sociedad decide especializarse en su implementación mientras que el resto de nosotros aprendemos a utilizar los resultados en forma de herramientas abstractas. De esta forma, el conjunto de herramientas abstractas de la sociedad se va expandiendo cada vez más y la capacidad de progresar de la sociedad se incrementa.
Veremos que los equipos de computación se construyen en una serie de niveles de herramientas abstractas. También veremos que el desarrollo de sistemas software de gran envergadura se lleva a cabo de una forma modular, de manera que cada módulo se emplea como una herramienta abstracta a la hora formar otros módulos de mayor complejidad. Además, la abstracción desempeña un papel importante en la tarea de hacer progresar a las propias Ciencias de la computación, haciendo a los investigadores centrar su atención en áreas concretas dentro
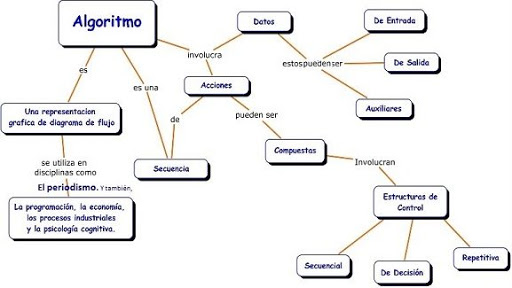
Informalmente, un algoritmo es un conjunto de pasos que define cómo hay que realizar una tarea.
Por ejemplo, existen algoritmos para cocinar (recetas), para encontrar el camino en una ciudad desconocida (direcciones), para hacer funcionar una lavadora (instrucciones que normalmente pueden en el manual), para tocar música (expresadas mediante partituras) y para realizar trucos de magia.
Por ejemplo:
Para que una máquina como una computadora pueda llevar a cabo una tarea, es preciso diseñar y representar un algoritmo de realización de dicha tarea y en una forma que sea compatible con la máquina.
A la representación de un algoritmo se la denomina programa.
Por comodidad de los seres humanos, los programas informáticos suelen imprimirse en papel o visualizarse en las pantallas de las computadoras. Sin embargo, para comodidad de las máquinas, los programas se codifican de una manera compatible con la tecnología a partir de la cual esté construida la máquina.
El proceso de desarrollo de un programa, de codificarlo en un formato compatible con la máquina y de introducirlo en una máquina se denomina programación.
Los programas y los algoritmos que representan se denominan colectivamente software, por contraste con la propia máquina que se conoce con el nombre de hardware.
El estudio de los algoritmos comenzó siendo un tema del campo de las matemáticas. De hecho, la búsqueda de algoritmos fue una actividad de gran importancia para los matemáticos mucho antes del desarrollo de las computadoras actuales.
El objetivo era determinar un único conjunto de instrucciones que describiera cómo resolver todos los problemas de un tipo concreto.
Uno de los ejemplos mejor conocidos de estas investigaciones pioneras es el algoritmo de división para el cálculo del cociente de dos números de varios dígitos.
Otro ejemplo es el algoritmo de Euclides descubierto por este matemático de la antigua Grecia que permite determinar el máximo común divisor de dos números enteros positivos.
Una vez que se ha encontrado un algoritmo para llevar a cabo una determinada tarea, la realización de esta ya no requiere comprender los principios en los que el algoritmo está basado. En lugar de ello, la realización de la tarea se reduce al proceso de seguir simplemente las instrucciones proporcionadas. (Podemos emplear el algoritmo de división para calcular un cociente o el algoritmo de Euclides para hallar el máximo común divisor sin necesidad de entender por qué funciona el algoritmo.)
En cierto sentido, la inteligencia requerida para resolver ese problema está codificada dentro del algoritmo.
Es esta capacidad de capturar y transmitir inteligencia (o al menos un comportamiento inteligente) por medio de algoritmos lo que nos permite construir máquinas que lleven a cabo tareas de utilidad.
En consecuencia, el nivel de inteligencia mostrado por las máquinas está limitado por la inteligencia que podamos transmitir mediante algoritmos. Solo podemos construir una máquina para llevar a cabo una tarea si existe un algoritmo que permita realizar esa tarea. A su vez, si no existe ningún algoritmo para resolver un problema, entonces la solución de ese problema cae fuera de la capacidad de las máquinas disponibles.
La identificación de las limitaciones de las capacidades algorítmicas terminó convirtiéndose en uno de los temas de las matemáticas en la década de 1930 con la publicación del teorema de incompletitud de Kurt Gödel.
Este teorema afirma, en esencia, que en cualquier teoría matemática que abarque nuestro sistema aritmético tradicional, hay enunciados cuya verdad o falsedad no puede establecerse por medios algorítmicos.
Por decirlo en pocas palabras, cualquier estudio completo de nuestro sistema aritmético, cae fuera de las capacidades de las actividades algorítmicas.
El enunciado de este hecho removió los cimientos de las matemáticas y el estudio de las capacidades algorítmicas que se inició a partir de ahí fue el comienzo del campo que hoy día conocemos como Ciencias de la computación.
De hecho, es el estudio de los algoritmos lo que forma la base fundamental de estas ciencias.
El progreso en el campo de las ciencias de la computación está haciendo que se difuminen muchas distinciones en las que nuestra sociedad ha basado sus decisiones en el pasado, y está poniendo en cuestión muchos de los principios largamente sostenidos en nuestra sociedad.
En el campo de las leyes, genera cuestiones relativas al grado con el que se puede ser poseedor de la propiedad intelectual y también en relación a los derechos y responsabilidades que acompañan dicha posesión.
En el campo de la ética, genera numerosas opciones que desafían los principios tradicionales en los que se basa el comportamiento social. En el campo de la acción de gobierno, genera debates relativos al grado con el que habría que regular la tecnología informática y sus aplicaciones. En el
terreno filosófico, genera un debate entre la presencia del comportamiento inteligente y la presencia de la propia inteligencia. Y en toda la sociedad genera disputas relativas a si las nuevas aplicaciones representan nuevas libertades o nuevos controles.
Aunque no forman parte de las Ciencias de la computación, estos temas son importantes para aquellos que estén pensando en desarrollar su carrera en el campo de la computación o en algún campo relacionado.
Los avances científicos han encontrado en ocasiones aplicaciones controvertidas, provocando un serio descontento a los investigadores que en ellos participaron. Además, una carrera llena de éxitos profesionales puede descarrilar rápidamente debido a una equivocación ética.
La capacidad de tratar con los dilemas planteados por los avances en la tecnología de computadoras también es importante para aquellos que no están directamente involucrados en esos avances. De hecho, la tecnología está permeando la sociedad de forma tan rápida que son pocas las personas que no se ven afectadas por los avances tecnológicos, si es que hay alguna.
el conocimiento técnico de las disciplinas científicas no proporciona por sí solo soluciones a todas las cuestiones planteadas.
Encontrar soluciones en estos casos a menudo requiere la capacidad de escuchar, de entender otros puntos de vista, de llevar a cabo un debate racional y de modificar la propia opinión a medida que se adquieren nuevas formas de ver las cosas.
Cuestiones sociales
Las siguientes cuestiones pretenden ser una guía para los problemas éticos/ sociales/legales asociados con el campo de la computación. El objetivo no es responder simplemente a estas cuestiones. El lector debería considerar también por qué las ha contestado de la forma en que lo ha hecho y analizar si sus justificaciones son coherentes entre las distintas cuestiones.
1. Generalmente se acepta la premisa de que nuestra sociedad es diferente de lo que sería si no se hubiera producido la revolución informática. ¿Es nuestra sociedad mejor de lo que hubiera sido sin dicha revolución? ¿Es nuestra sociedad peor? ¿Sería diferente su respuesta si su posición dentro de la sociedad fuera distinta?
2. ¿Es aceptable participar en la sociedad técnica actual sin hacer un esfuerzo por comprender los fundamentos de dichas tecnologías? Por ejemplo, ¿cree que los ciudadanos de un país democrático, cuyos votos determinan a menudo cómo se apoyará y se utilizará la tecnología, tienen la obligación de tratar de entender dicha tecnología? ¿Depende su respuesta de la tecnología que se esté considerando? Por ejemplo, ¿sería su respuesta igual a la hora de considerar la tecnología nuclear que a la hora de considerar la tecnología de computadoras?
3. Utilizando dinero en efectivo en las transacciones financieras, las personas han dispuesto tradicionalmente de la opción de gestionar sus asuntos financieros sin que les cobraran comisiones de servicio. Sin embargo, a medida que se va automatizando una parte cada vez mayor de nuestra economía, las instituciones financieras aplican comisiones de servicio para el acceso a
estos sistemas automatizados. ¿Cree que existe un punto en que dichas comisiones restringen de manera no equitativa el acceso de las personas a la economía? Por ejemplo, suponga que un empresario paga a sus empleados exclusivamente mediante un cheque y que todas las entidades financieras aplican una comisión de servicio a las operaciones de cobro y depósito de cheques. ¿Implicaría esto un trato injusto hacia los empleados? ¿Qué sucedería si un empresario insistiera en pagar únicamente mediante transferencia a una cuenta corriente?
4. En el contexto de la televisión interactiva, ¿en qué grado debería permitirse a las empresas recopilar información de los niños (quizá mediante un formato de juego interactivo)? Por ejemplo, ¿debería permitirse a las empresas obtener un informe de los niños sobre los hábitos de compra de sus padres? ¿Debería permitírseles obtener información acerca del propio
niño?
5. ¿Hasta qué punto debería un gobierno regular la tecnología de computadoras y sus aplicaciones? Considere, por ejemplo, los problemas planteados en las Cuestiones 3 y 4. ¿Qué razones son las que justificarían la regulación gubernamental?
6. ¿En qué grado pueden afectar a las generaciones futuras nuestras decisiones concernientes a la tecnología en general y a la tecnología de las computadoras en particular?
7. A medida que avanza la tecnología, nuestro sistema educativo se ve enfrentado al desafío de reconsiderar el nivel de abstracción con el que se presentan los temas. Muchas de las cuestiones que se plantean son del tipo de si una capacidad sigue siendo necesaria o si, por el contrario, debería permitirse a los estudiantes utilizar una herramienta abstracta. Por ejemplo, a los
estudiantes de trigonometría ya no se les enseña a calcular los valores de las funciones trigonométricas utilizando tablas. En lugar de ello, emplean calculadoras como herramientas abstractas para determinar dichos valores. Algunas personas argumentan que también debería prescindirse de enseñar el algoritmo de división sustituyéndolo por una abstracción. ¿Qué otros temas se ven afectados por controversias similares? ¿Cree que los procesadores de texto modernos eliminan la necesidad de dominar la ortografía?
¿Cree que el uso de la tecnología de vídeo hará que desaparezca algún día la necesidad de leer?
8. El concepto de biblioteca pública se basa, en gran medida, en la premisa de que todos los ciudadanos de una democracia deben tener acceso a la información. A medida que se disemina y almacena cada vez más información mediante tecnología de computadoras, ¿cree que el acceso a esta tecnología se convierte en un derecho de todo individuo? Si esto es así, ¿deberían ser las bibliotecas públicas el canal a través del cual se proporcionara dicho acceso?
9. ¿Qué problemas éticos surgen en una sociedad que depende del uso de herramientas abstractas? ¿Existen casos en los que no resulte ético utilizar un producto o servicio sin entender cómo funciona? ¿Y existen casos en los que no resulta ético utilizar un producto o servicio sin saber cómo se produce o suministra?, ¿o sin entender cuáles son las consecuencias de su uso?
10. A medida que nuestra sociedad se automatiza cada vez, resulta más fácil para los gobiernos vigilar las actividades de sus ciudadanos. ¿Cree que esto es bueno o es malo?
11. ¿Qué tecnologías imaginadas por George Orwell (Eric Blair) en su novela 1984 se han hecho realidad? ¿Se están utilizando en la forma en que Orwell predijo?
12. Si existiera una máquina del tiempo, ¿en qué periodo de la historia querría vivir? ¿Hay alguna tecnología actual que le gustaría llevar consigo? ¿Podría llevar esas tecnologías consigo sin llevar al mismo tiempo otras tecnologías? ¿Hasta que punto puede separarse una tecnología de otra? ¿Es coherente protestar contra el calentamiento global y, sin embargo, aceptar los nuevos tratamientos médicos?
13. Suponga que su trabajo le obligara a vivir en un país con otra cultura. ¿Debería continuar aplicando los principios éticos de su cultura nativa o adoptar la ética de la cultura de su país anfitrión? ¿Depende su respuesta de si los temas planteados afectan a la forma de vestir o a los derechos humanos? ¿Qué estándares éticos deberían prevalecer si continúa residiendo en su país nativo pero tiene que hacer negocios con un país extranjero, con una cultura diferente?
14. ¿Cree que la sociedad se ha hecho demasiado dependiente de las aplicaciones informáticas para el comercio, las comunicaciones o las relaciones sociales? Por ejemplo, ¿cuáles serían las consecuencias de una interrupción prolongada en el servicio de Internet y/o de telefonía móvil?
15. La mayor parte de los teléfonos inteligentes son capaces de identificar la ubicación del teléfono por medio del sistema GPS. Esto permite a las aplicaciones proporcionar información específica de la ubicación (como por ejemplo las noticias locales, el pronóstico del tiempo en esa localidad o
información acerca de las empresas situadas en las proximidades), basándose en la ubicación actual del teléfono. Sin embargo, dichas capacidades GPS también pueden permitir a otras aplicaciones informar acerca de la ubicación del teléfono a otras personas. ¿Es eso bueno? ¿Qué posibles abusos podrían darse si alguien conociera la ubicación del teléfono (y por tanto nuestra ubicación)?
La representación de sonidos ha adquirido una importancia notable debido esencialmente a la infinidad de aplicaciones multimedia tanto autónomas como en la web.
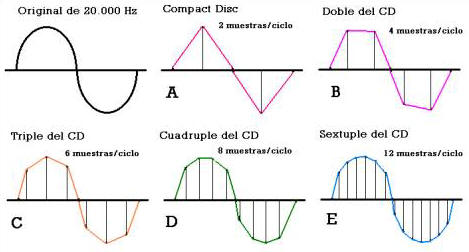
El método más genérico de codificación de la información de audio para almacenamiento y manipulación en computadora es mostrar la amplitud de la onda de sonido en intervalos regulares y registrar las series de valores obtenidos.
La señal de sonido se capta mediante micrófonos o dispositivos similares y produce una señal analógica que puede tomar cualquier valor dentro de un intervalo continúo determinado.
En un intervalo de tiempo continuo se dispone de infinitos valores de la señal analógica, que es necesario almacenar y procesar, para lo cual se recurre a una técnica de muestreo.
Las muestras obtenidas se digitalizan con un conversor analógico-digital, de modo que la señal de sonido se representa por secuencias de bits (por ejemplo, 8 o 16) para cada muestra.
Esta técnica es similar a la utilizada, históricamente, por las comunicaciones telefónicas a larga distancia. Naturalmente, dependiendo de la calidad de sonido que se requiera, se necesitarán más números de bits por muestra, frecuencias de muestreo más altas y lógicamente más muestreos por períodos de tiempo.
Como datos de referencia puede considerar que para obtener reproducción de calidad de sonido de alta fidelidad para un disco CD de música, se suele utilizar, al menos, una frecuencia de muestreo de 44.000 muestras por segundo.
Los datos obtenidos en cada muestra se codifican en 16 bits (32 bits para grabaciones en estéreo). Como dato anecdótico, cada segundo de música grabada en estéreo requiere más de un millón de bits.
Un sistema de codificación de música muy extendido en sintetizadores musicales es MIDI (Musical InstrumentsDigital Interface) que se encuentra en sintetizadores de música para sonidos de videojuegos, sitios web, teclados electrónicos, etc.
Las imágenes se adquieren mediante periféricos especializados tales como escáneres, cámaras digitales de vídeo, cámaras fotográficas, etc. Una imagen, al igual que otros tipos de información, se representa por patrones de bits, generados por el periférico correspondiente.
Existen dos métodos básicos para representar imágenes:
mapas de bits y mapas de vectores.
Los mapas de bits, considera una imagen como una colección de puntos, cada uno de los cuales se llama pixel (abreviatura de “picture element”).
Una imagen en blanco y negro se representa como una cadena larga de bits que representan las filas de píxeles en la imagen, donde cada bit es bien 1 o bien 0, dependiendo de que el pixel correspondiente sea blanco o negro.
En el caso de imágenes en color, cada pixel se representa por una combinación de bits que indican el color del pixel.
Cuando se utilizan técnicas de mapas de bits, el patrón de bits resultante se llama mapa de bits, significando que el patrón de bits resultante que representa la imagen es poco más que un mapa de la imagen.
Muchos de los periféricos de computadora —tales como cámaras de vídeo, escáneres, etc.— convierten imágenes de color en formato de mapa de bits.
Los formatos más utilizados en la representación de imágenes se muestran en la Tabla 1.4.
Mapas de vectores.
Otros métodos de representar una imagen se fundamentan en descomponer la imagen en una colección de objetos tales como líneas, polígonos y textos con sus respectivos atributos o detalles (grosor, color, etc.).
La información en formato de texto se representa mediante un código en el que cada uno de los distintos símbolos del texto (tales como letras del alfabeto o signos de puntuación) se asignan a un único patrón de bits.
El texto se representa como una cadena larga de bits en la cual los sucesivos patrones representan los sucesivos símbolos del texto original.
En resumen, se puede representar cualquier información escrita (texto) mediante caracteres.
Los caracteres que se utilizan en computación suelen agruparse en cinco categorías:
1. Caracteres alfabéticos (letras mayúsculas y minúsculas A, B, C, D, E, … X, Y, Z, a, b, c, … , X, Y, Z
2. Caracteres numéricos (dígitos del sistema de numeración). 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 sistema decimal
3. Caracteres especiales (símbolos ortográficos y matemáticos no incluidos en los grupos anteriores). { } Ñ ñ ! ? & > # ç …
4. Caracteres geométricos y gráficos (símbolos o módulos con los cuales se pueden representar cuadros, figuras geométricas, iconos, etc. | —| ||—— ♠ ∼ …
5. Caracteres de control (representan órdenes de control como el carácter para pasar a la siguiente línea [NL] o para ir al comienzo de una línea [RC, retorno de carro, “carriage return, CR”] emitir un pitido en el terminal [BEL], etc.).
Al introducir un texto en una computadora, a través de un periférico, los caracteres se codifican según un código de entrada/salida de modo que a cada carácter se le asocia una determinada combinación de n bits.
Los códigos más utilizados en la actualidad son:
EBCDIC, ASCII y Unicode.
• Código EBCDIC (Extended Binary Coded Decimal Inter Change Code).
Este código utiliza n = 8 bits de forma que se puede codificar hasta m = 28 = 256 símbolos diferentes. Éste fue el primer código utilizado para computadoras, aceptado en principio por IBM.
• Código ASCII (American Standard Code for Information Interchange).
El código ASCII básico utiliza 7 bits y permite representar 128 caracteres (letras mayúsculas y minúsculas del alfabeto inglés, símbolos de puntuación, dígitos 0 a 9 y ciertos controles de información tales como retorno de carro, salto de línea, tabulaciones, etc.). Este código es el más utilizado en computadoras, aunque el ASCII ampliado con 8 bits permite llegar a 28 (256) caracteres distintos entre ellos ya símbolos y caracteres especiales de otros idiomas como el español.
Código Unicode
Aunque ASCII ha sido y es dominante en la representación de los caracteres, hoy día se requiere de la necesidad de representación de la información en muchas otras lenguas, como el portugués, español, chino, el japonés, el árabe, etc. Este código utiliza un patrón único de 16 bits para representar cada símbolo, que permite 216 bits o sea hasta 65.536 patrones de bits (símbolos) diferentes.
Desde el punto de vista de unidad de almacenamiento de caracteres, se utiliza el archivo (fichero).
Un archivo consta de una secuencia de símbolos de una determinada longitud codificados utilizando ASCII o Unicode y que sedenomina archivo de texto.
Es importante diferenciar entre archivos de texto simples que son manipulados por losprogramas de utilidad denominados editores de texto y los archivos de texto más elaborados que se producen por los procesadores de texto, tipo Microsoft Word.
Ambos constan de caracteres de texto, pero mientras el obtenido con el editor de texto, es un archivo de texto puro que codifica carácter a carácter, el archivo de texto producido por un procesador de textos contiene números, códigos que representan cambios de formato, de tipos de fuentes de letra y otros, e incluso pueden utilizar códigos propietarios distintos de ASCII o Unicode.
Representación de valores numéricos
El almacenamiento de información como caracteres codificados es ineficiente cuando la información se registra como numérica pura.
Veamos esta situación con la codificación del número 65; si se almacena como caracteres ASCII utilizando un byte por símbolo, se necesita un total de 16 bits, de modo que el número mayor que se podía almacenar en 16 bits (dos bytes) sería 99.
Sin embargo, si utilizamos notación binaria para almacenar enteros, el rango puede ir de 0 a 65.535 (216 – 1) para números de 16 bits. Por consiguiente, la notación binaria (o variantes de ellas) es la más utilizada para el almacenamiento de datos numéricos codificados.
La solución que se adopta para la representación de datos numéricos es la siguiente:
Al introducir un número en la computadora se codifica y se almacena como un texto o cadena de caracteres, pero dentro del programa a cada dato se le envía un tipo de dato específico y es tarea del programador asociar cada dato al tipo adecuado correspondiente a las tareas y operaciones que se vayan a realizar con dicho dato.
El método práctico realizado por la computadora es que una vez definidos los datos numéricos de un programa, una rutina (función interna) de la biblioteca del compilador (traductor) del lenguaje de programación se encarga de transformar la cadena de caracteres que representa el número en su notación binaria.
Existen dos formas de representar los datos numéricos: números enteros o números reales.
Representación de enteros
Los datos de tipo entero se representan en el interior de la computadora en notación binaria. La memoria ocupada por los tipos enteros depende del sistema, pero normalmente son dos, bytes (en las versiones de MS-DOS y versiones antiguas de Windows y cuatro bytes en los sistemas de 32 bits como Windows o Linux). Por ejemplo, un entero almacenado en 2 bytes (16 bits):1000 1110 0101 1011
Los enteros se pueden representar con signo (signed, en C++) o sin signo (unsigned, en C++); es decir, números positivos o negativos.
Normalmente, se utiliza un bit para el signo. Los enteros sin signo al no tener signo pueden contener valores positivos más grandes. Normalmente, si un entero no se especifica “con/sin signo” se suele asignar con signo por defecto u omisión.
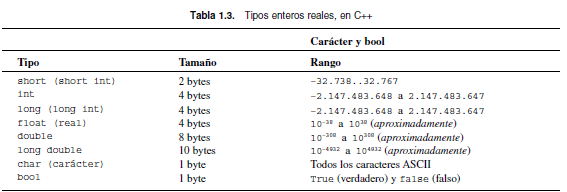
El rango de posibles valores de enteros depende del tamaño en bytes ocupado por los números y si se representan con signo o sin signo (la Tabla 1.3 resume características de tipos estándar en C++).
Representación de reales
Los números reales son aquellos que contienen una parte decimal como 2,6 y 3,14152.
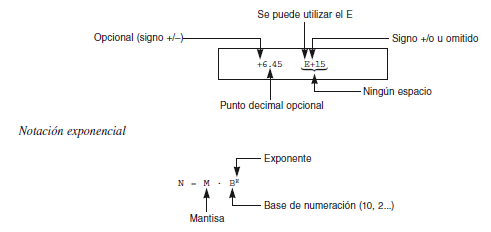
Los reales se representan en notación científica o en coma flotante; por esta razón en los lenguajes de programación, como C++, se conocen como números en coma flotante.
Existen dos formas de representar los números reales. La primera se utiliza con la notación del punto decimal (ojo en el formato de representación español de números decimales, la parte decimal se representa por coma).
La segunda forma para representar números en coma flotante en la notación científica o exponencial, conocida también como notación E.
Esta notación es muy útil para representar números muy grandes o muy pequeños.
Representación de caracteres
Un documento de texto se escribe utilizando un conjunto de caracteres adecuado al tipo de documento. En los lenguajes de programación se utilizan, principalmente, dos códigos de caracteres.
El más común es ASCII (American Standard Code for Information Interchange) y algunos lenguajes, tal como Java, utilizan Unicode (www.unicode.org).
Ambos códigos se basan en la asignación de un código numérico a cada uno de los tipos de caracteres del código.
En C++, los caracteres se procesan normalmente usando el tipo char, que asocia cada carácter a un código numérico que se almacena en un byte.
El código ASCII básico que utiliza 7 bits (128 caracteres distintos) y el ASCII ampliado a 8 bits (256 caracteres distintos) son los códigos más utilizados. Así se pueden representar caracteres tales como ‘A’, ‘B’, ‘c’, ‘$’, ‘4’, ‘5’, etc.
La Tabla 1.3, recoge los tipos enteros, reales y carácter utilizados en C++, la memoria utilizada (número de bytes ocupados por el dato) y el rango de números.
Una computadora es un sistema para procesar información de modo automático.
Un tema vital en el proceso de funcionamiento de una computadora es estudiar la forma de representación de la información en dicha computadora.
Es necesario considerar cómo se puede codificar la información en patrones de bits que sean fácilmente almacenables y procesables por los elementos internos de la computadora.
Las formas de información más significativas son: textos, sonidos, imágenes y valores numéricos y, cada una de ellas presentan peculiaridades distintas.
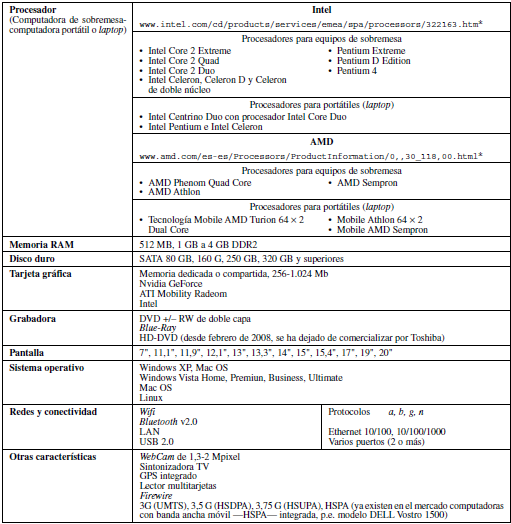
Las computadoras personales que en el primer trimestre de 2008 se comercializan para uso doméstico y en oficinas o en las empresas suelen tener características comunes, y es normal que sus prestaciones sean similares a las utilizadas en los laboratorios de programación de Universidades, Institutos Tecnológicos y Centros de Formación Profesional.
Por estas razones en la Tabla 1.2 se incluyen recomendaciones de características técnicas medias que son, normalmente, utilizadas, para prácticas de aprendizaje de programación, por el alumno o por el lector autodidacta, así como por profesionales en su actividad diaria.